Guide to TUdatalib for administrators of the departments
Status: 02.06.2026
licensed under CC0 1.0, no copyright protection.
Scope
This guideline is primarily intended for users of TU Darmstadt. Partner universities that also use this system may have different rules. Find more about those here: Contact
1. About this admin guide
The following instructions are aimed at administrators of the individual departments and provide an overview of the functions and workflows of TUdatdalib. Alternatively, you can find further information in our FAQ or in the Users Guide of TUdatalib.
For questions or suggestions we are always at your disposal.
2. Costs
The use of TUdatalib is free of charge up to a total volume of 2 TB of new data per year and faculty of the TU.
For larger quantities of new data, a one-time cost contribution by the faculty is required for data volumes exceeding 2 TB. This is currently at € 250 / TB for 10 years of archiving. Invoicing is handled by the HRZ. TUdatalib sends notification emails to the admins of an community when the free data volume is 90% and 100% full.
3. Organizational model of TUdatalib
3.1 The individual entities
In TUdatalib, the organizational units of the TU are preset as communities, sorted by faculties, institutes and subject communities. If a faculty or similar is missing, please contact us. Communities can be subdivided into further sub-communities. There should be at least one administrator (two are recommended) for each community in TUdatalib. Administrators manage the roles and rights for their community and can create collections.
Any number of collections can be created within an community in order to map different authorization groups. Any number of datasets (items) can be created in a collection. Each dataset contains a descriptive set of metadata, any number of individual files (bitstreams) and a persistent identifier (see section Assignment of DOIs below).

(Source: https://wiki.lyrasis.org/display/DSDOC6x/Functional+Overview)
3.2 Rights and role management
In TUdatalib, rights and roles are assigned exclusively to groups (and not to individual users). Users can be assigned four different roles by being included in these authorization groups:
- Administrator: (see also in particular the section "Administration of data sets"). The main rights include:
- creating collections
- assigning and managing roles and rights
- editing metadata
- requesting DOIs
- mirroring datasets between collections
- Reader: Users who are allowed to view the datasets in a collection. This is the default right for users who were automatically assigned to an community after logging in.
- Submitter: Users who are allowed to submit new datasets to a collection.
- Reviewer: Users who are allowed to accept or reject submitted datasets and edit their metadata.
4. workflows in the TUdatalib web interface
4.1 Metadata assignment for the community
Once the administrator has been determined for a community, they can edit the metadata of their community.
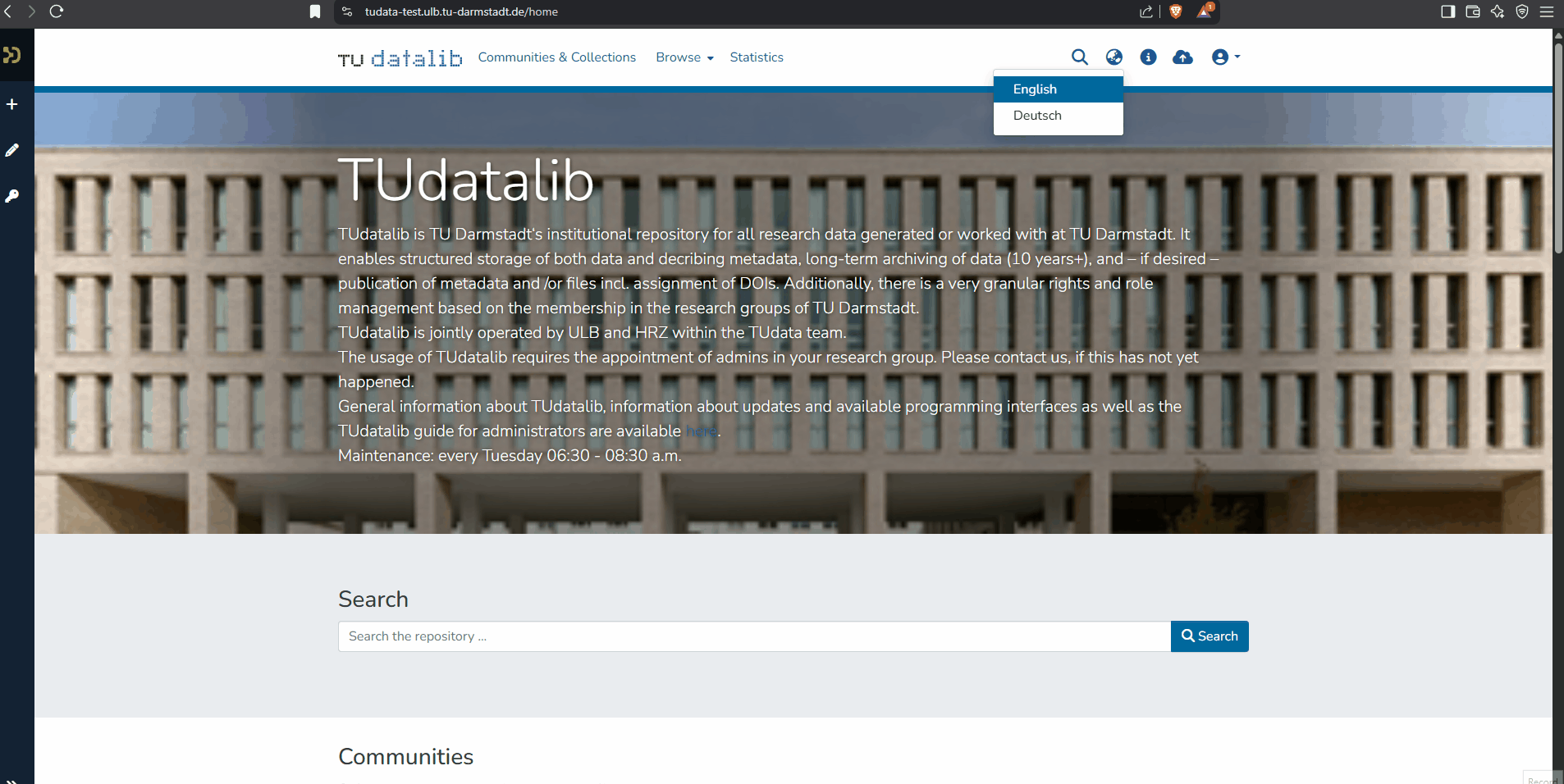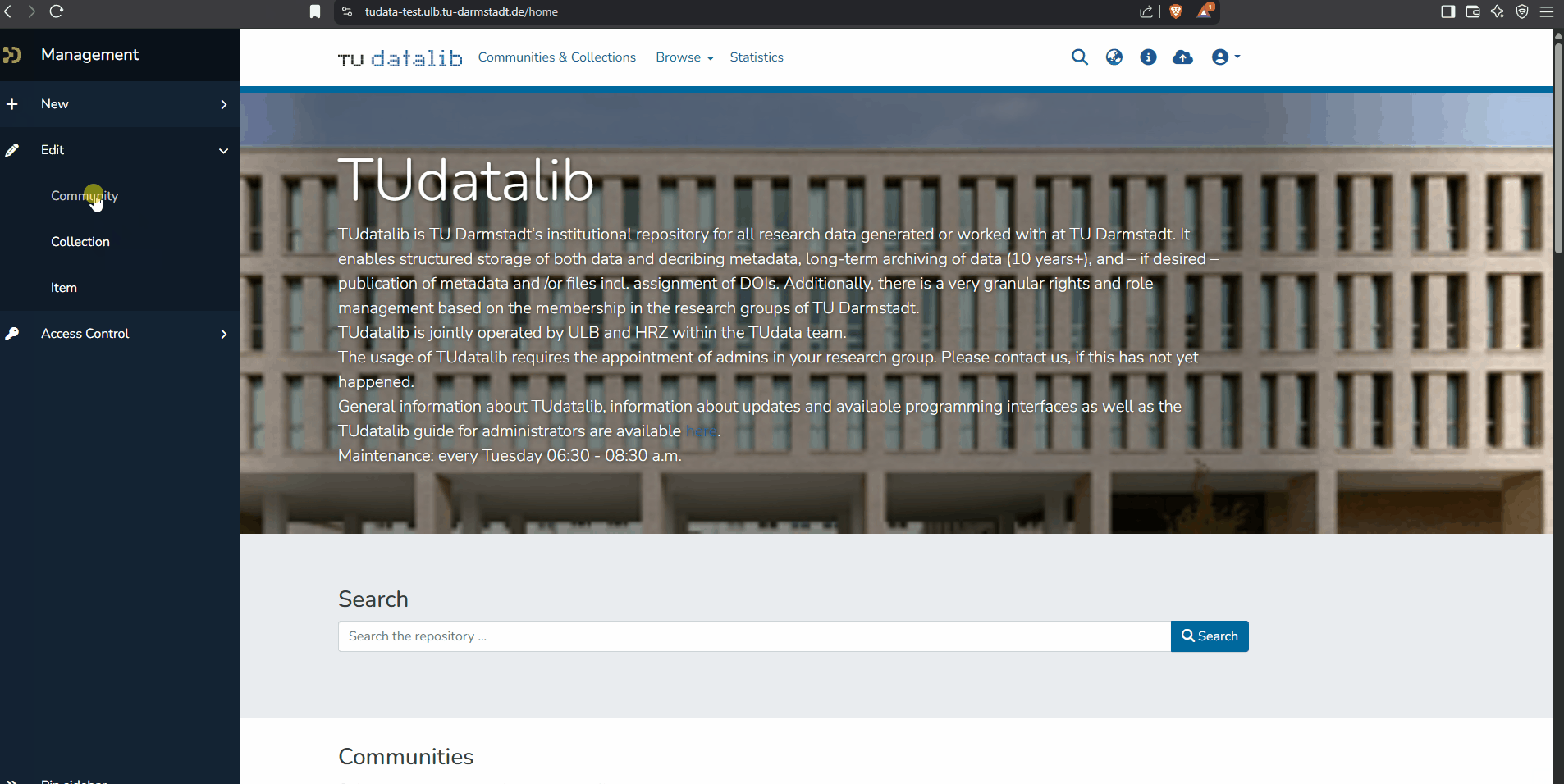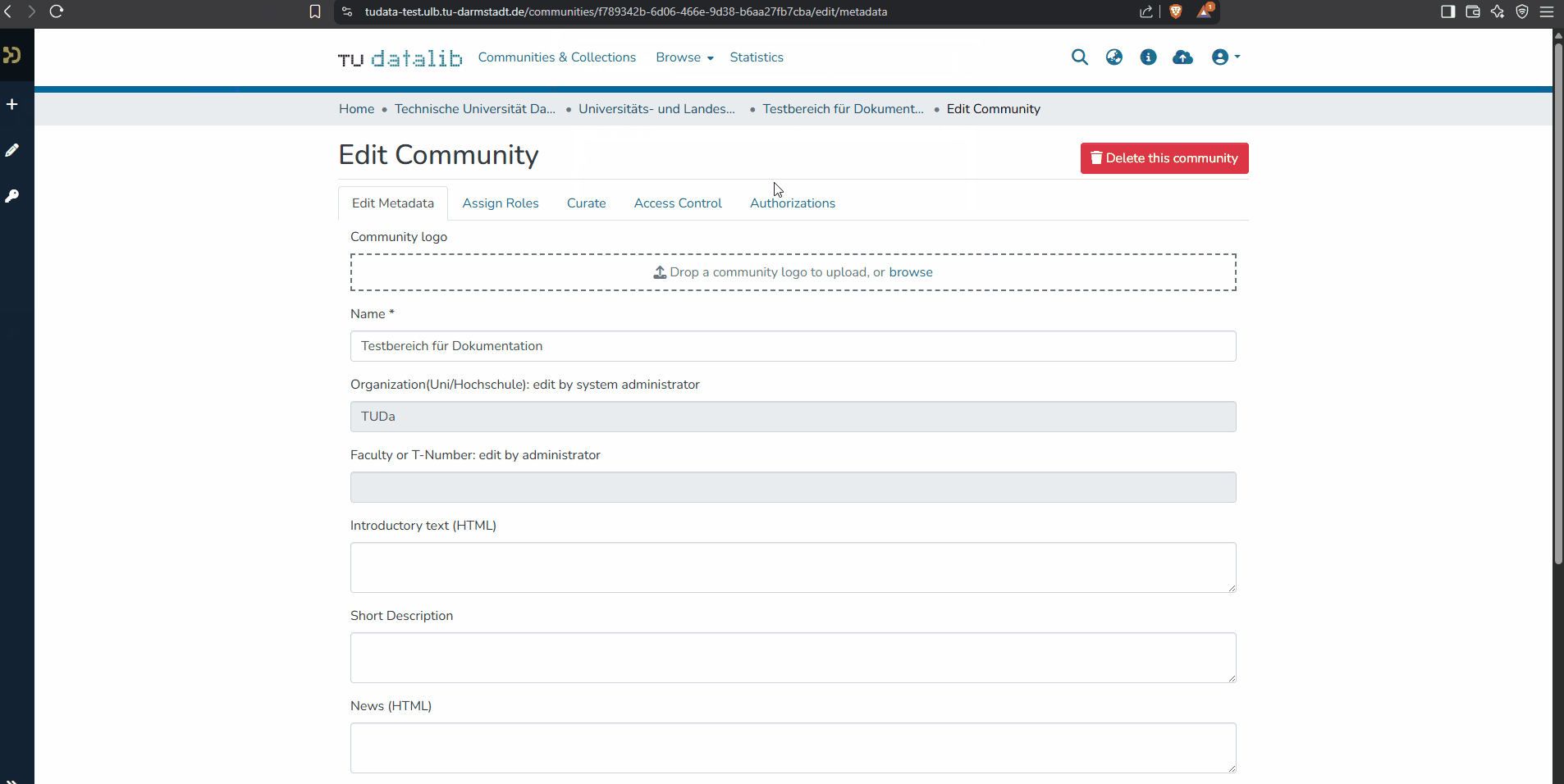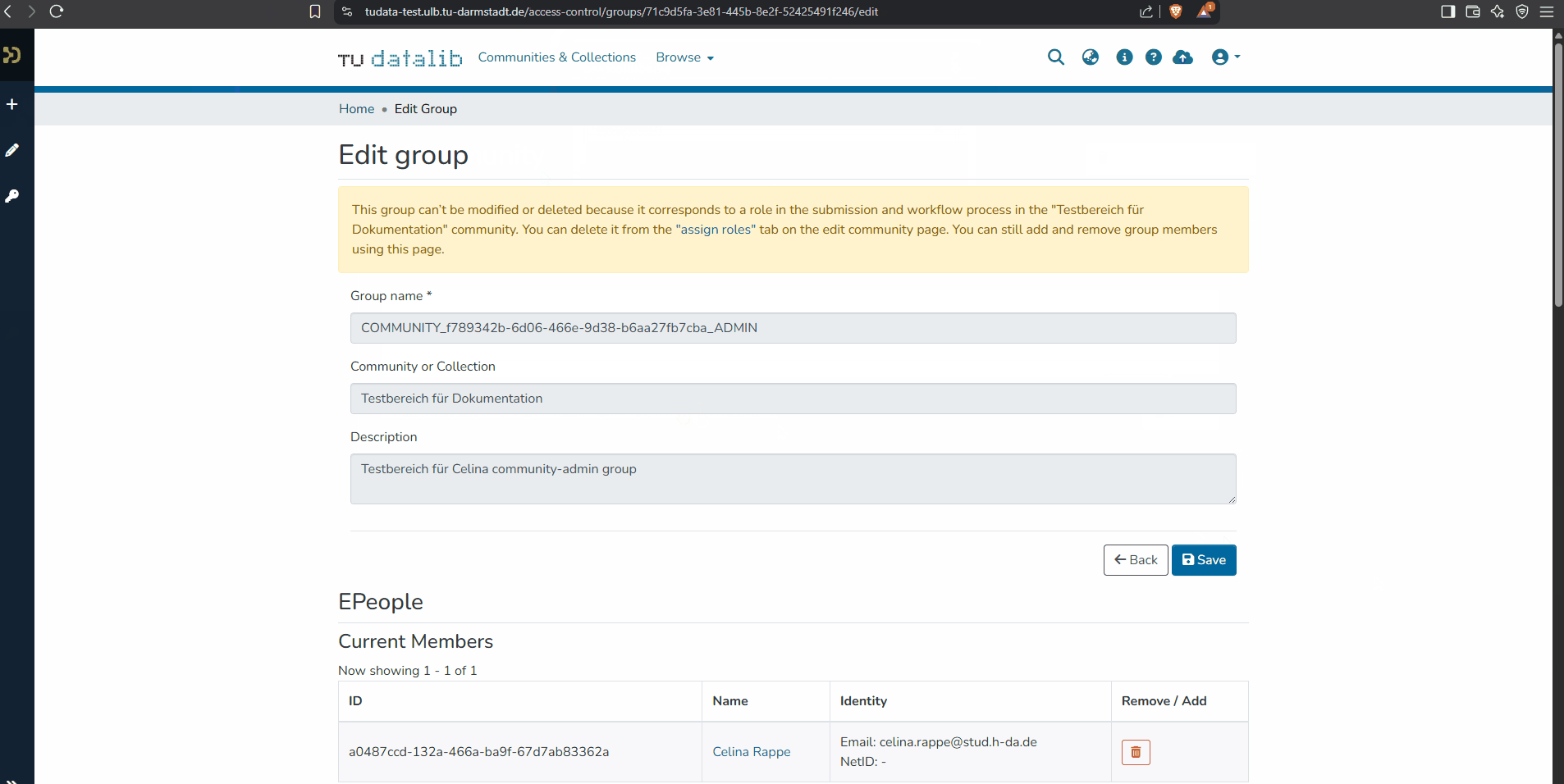
To edit the metadata of your community, navigate from the start page via the navigation bar located on the left side of the screen to "Edit" and select the sub-item "community". Then search for your desired community. By clicking on your desired community, you will be forwarded directly to the editing form - here you can enter and maintain a community description with a name and an introductory text (also in HTML), a community logo, etc.
4.2 Assignment of administrator rights
To grant additional users administrator rights, the authorization group must be expanded. Navigate to the relevant community or collection via the navigation bar under "Edit" and click on "Assign roles". You will then be shown a group name that looks somewhat like this: COMMUNITY_xxx_ADMIN. You can edit the group by clicking on the group name. Users can be found via the search bar by entering their surname or first name and added as members if they have already logged in to TUdatalib.
You can then manage the members of this group. Members of the group can be individual users, but also groups of users.
- If a user cannot be found in the user list, please make sure that the user has logged in to TUdatalib at least once before.
- If you always want to assign admin rights for different sub-communities to the same group, please contact us. The system administrator can predefine such a group in TUdatalib.
4.3 Creating substructures (sub-communities & -collections) in a community
4.3.1 Creating a sub-community within an community
It is possible (but not necessary) to create sub-communities within an community. To do this, use the navigation bar under "New" to navigate to the community in which you want to create a sub-community. Click on the section name to open a form in which you can enter the name, description and other relevant metadata for your section. Finally, click on "Submit" to confirm your entry.

A sub-community can be edited in the same way as a community and has the same metadata fields.
4.3.2 Creating a collection within a community
It is essential to create at least one collection in order to be able to create datasets in an community (see 5.1). Once the user group with admin rights has been defined, you can proceed to create a collection in your community. To do this, navigate to the "New" item via the navigation bar on the left and select the "Collection" sub-item. Here you have the option of deciding in which community the collection should be created. As soon as you click on the respective community, you will be forwarded to a form in which you can create the collection.
4.4 Metadata assignment and initial rights settings for the collection
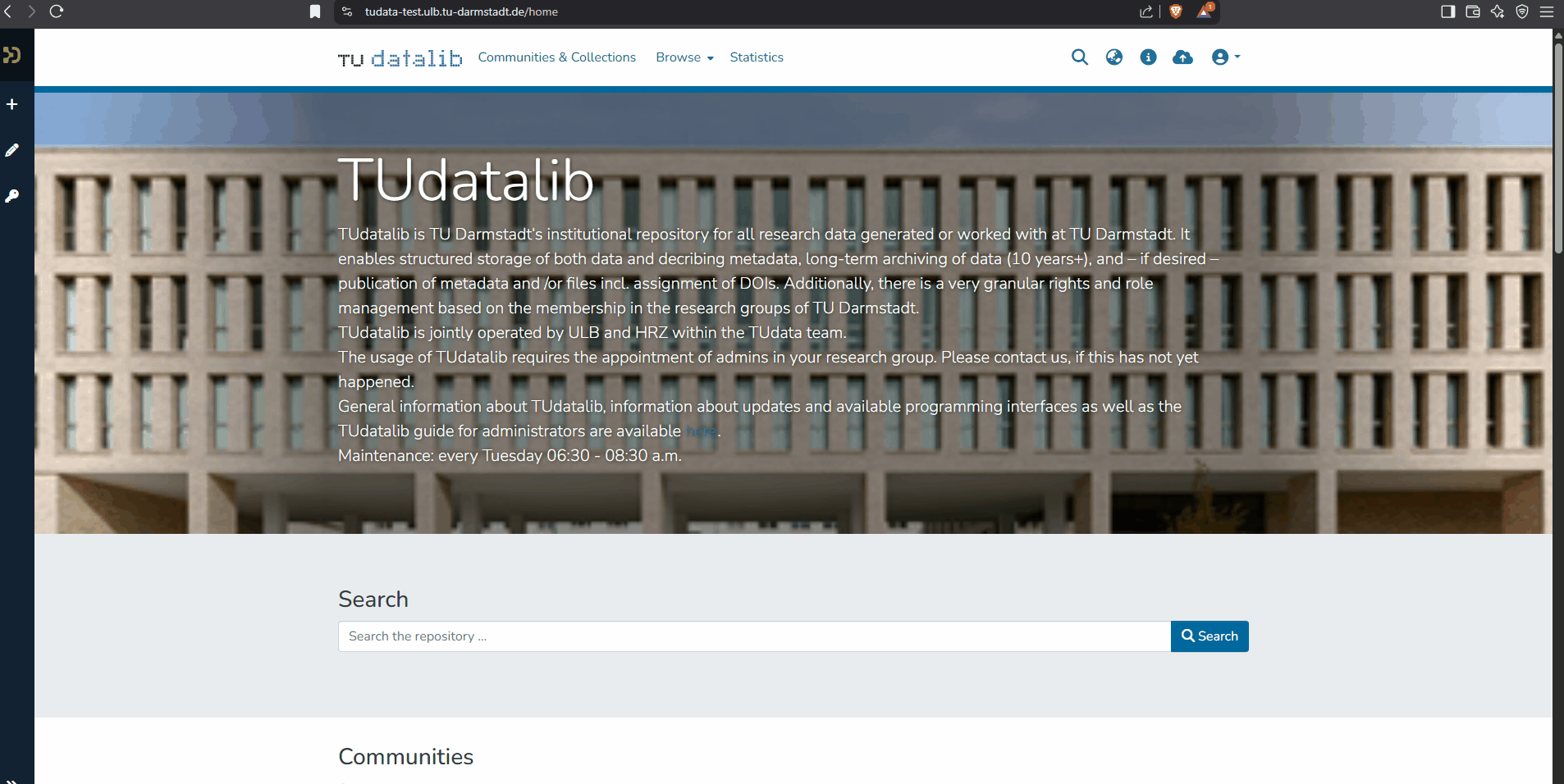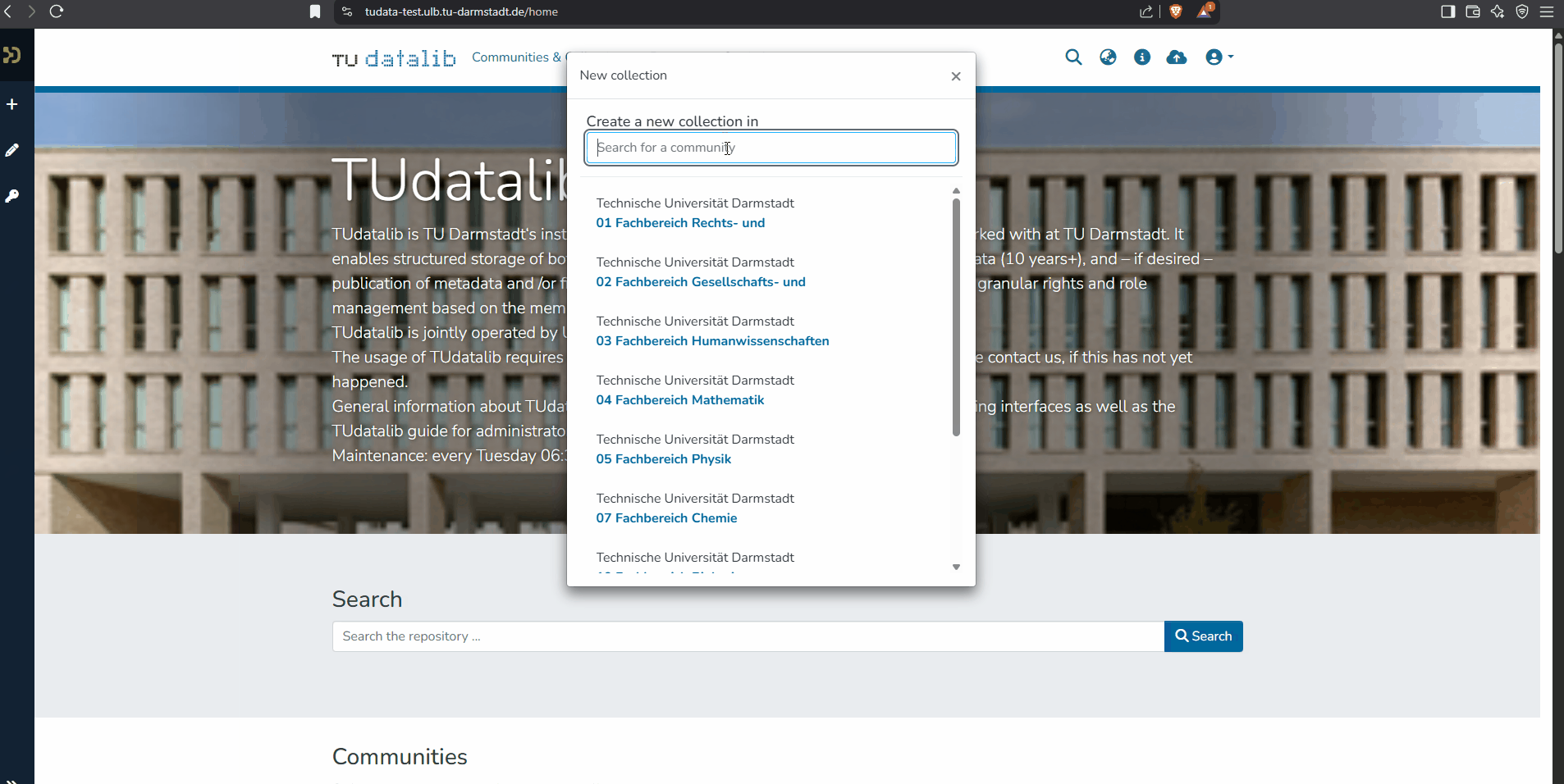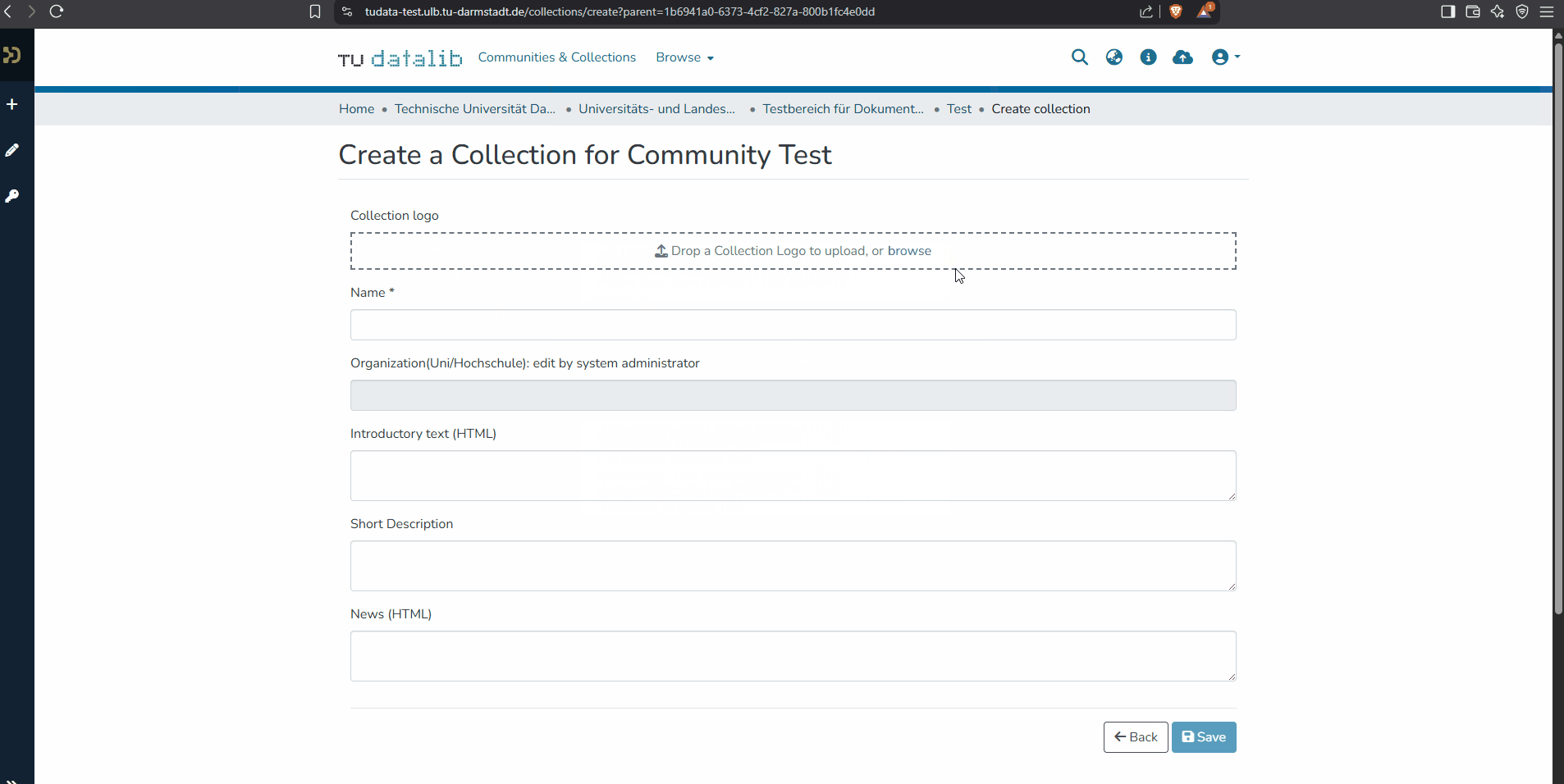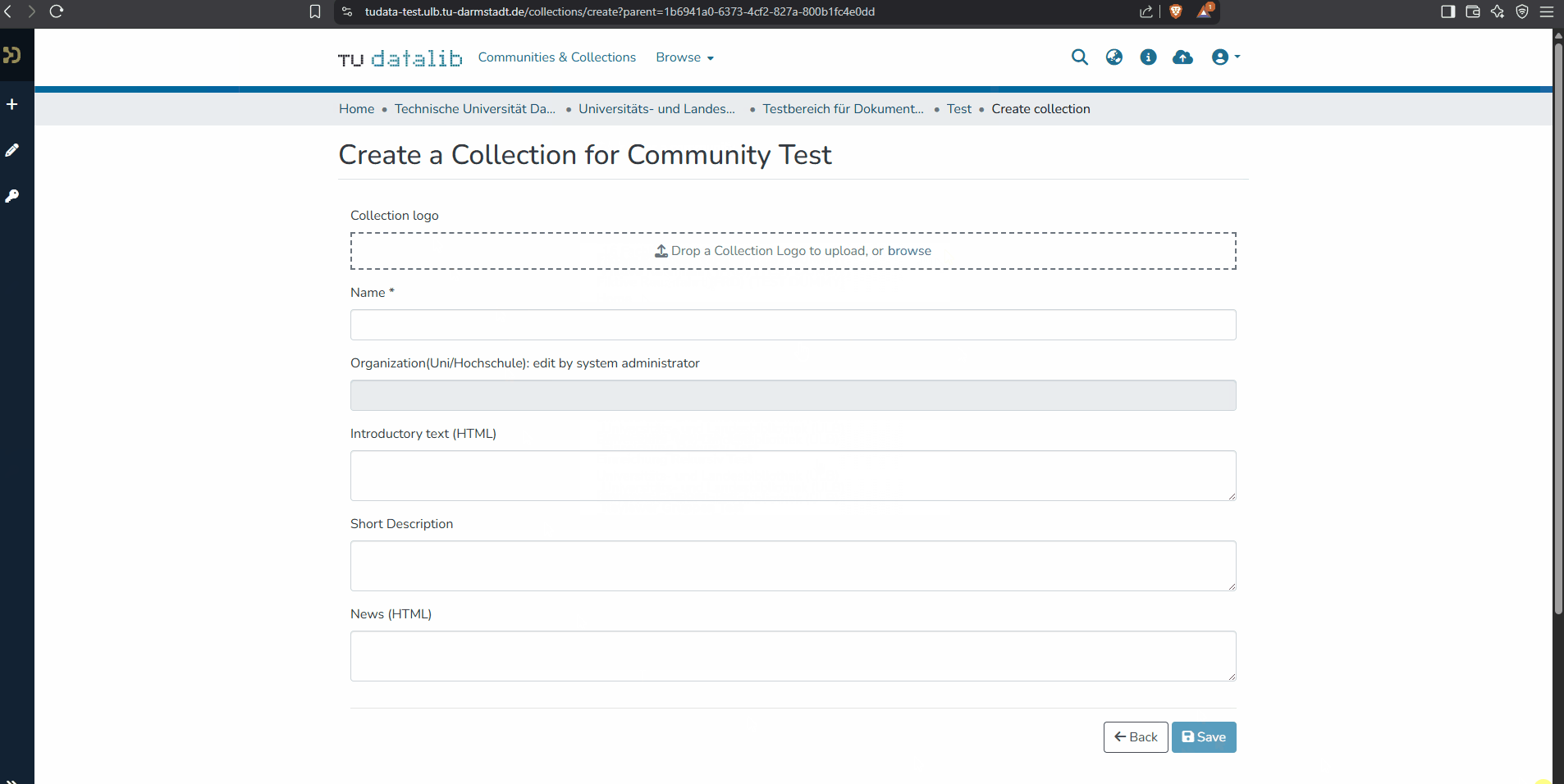
Various metadata can be specified when creating a new collection. This includes the name of the collection, a short description, an introductory text (also in HTML) and the possibility to outline news. You can edit the metadata using the navigation bar on the left under "Edit" and by navigating to the respective collection.
You also have the option to set initial rights settings for the collection:
- Submission permissions can be granted to individuals who log in using their TU ID and are assigned to the respective working group (Fachgebiet) in the TU IDM system.
- Read access can be granted to these users, or the collection can be made public. Please note that (except in very complex configurations) users with submission rights always have read access as well.
- A review process can be set up for new records, with the relevant community administrators acting as reviewers
The sub-item "Content source" shows whether it is a standard TUdatalib collection or whether the collection obtains its content from an external source via harvesting.
4.5 Assigning rights and roles within a collection
In the sub-item "Assign roles", you can set who is allowed to view the files and metadata of the data sets, for example. To do this, click on the group name (COMMUNITY_xxx_ADMIN) and select the desired person. Four different roles can be assigned to users and groups: Administrator, Submitter, Accessor and Reviewer. The group of authorized users is automatically created when a new collection is created and by default contains a group to which all members of a subject community are automatically added based on the organizational unit associated with the TU ID (after the first login to TUdatalib).
All community administrators are always also collection administrators for all collections in their community. Collection administrators do not automatically have the role of an editor, as this role does not necessarily have to be filled.
To further edit rights and roles within a collection, navigate from the navigation bar on the left under "Edit" to the collection you wish to edit.
4.6 Assigning roles for editors via groups
When assigning the roles mentioned above, a group must be created for each assigned role. This is automatically given a name of the form COMMUNITY_xxx_
| Role | Name of the associated group | Example | Rights of the group members |
|---|---|---|---|
| Administrator:innen | COLLECTION_ |
COLLECTION_ae910c2b-d734-4777-9571-0f116d7ff41a_ADMIN | • Creating collections • Assigning and managing roles and rights • Accept and reject created data sets • Edit metadata • request DOI • Mirror datasets from other collections if they have the same rights as the datasets to be mirrored |
| Access authorized:r | COLLECTION_ |
COLLECTION_9c4f4d8e-6c6b-43ea-b4c1-88b46cbc6af3_DEFAULT_ITEM_READ | • Read access, content cannot be changed • Download data sets |
| Submitter:r | COLLECTION_ |
COLLECTION_9c4f4d8e-6c6b-43ea-b4c1-88b46cbc6af3_SUBMIT | • Submission of datasets in TUdatalib |
| editor:in | COLLECTION_ |
COLLECTION_9c4f4d8e-6c6b-43ea-b4c1-88b46cbc6af3_WORKFLOW_ROLE_editor | • Acceptance or rejection of submitted datasets • Editing their metadata |
If one of the four authorization groups for a community does not yet exist (only the group for authorized users is created automatically), it can be created under "Assign roles" under "Edit collection". To do this, click on "Create" to create the group.
The administrator of a community or collection can edit the members of the groups, e.g. add users or a subgroup.
To add a user to a group, they must be found using the search function and then added using the "Add" button.

Attention
To ensure scientific traceability, only users who are clearly identifiable as a real person may be assigned roles with write permissions. This means that users who were created as external users via a function mailbox cannot become administrators or editors and may not be included in the corresponding authorization groups.
4.7 Administration of data sets
Administration rights include further authorizations once the submission has been approved. Administrators can request DOIs, edit access rights for the datasets (metadata and files) after archiving, identify older versions of datasets and mirror them in other collections.
You can access the screen for managing data records either by clicking on the pencil icon in the top right corner of the respective data record or by selecting Edit -> Item in the navigation menu and then searching for the corresponding data record. For most of the functions described here, you will then need to switch to the “Status” tab.
Here, you will also find further administration options, including discarding, moving to another collection or making the dataset invisible.
4.7.1 Publication of data sets
If all datasets in a collection are to be publicly visible, the procedure described in section 4.6 is recommended, in which the DEFAULT_READ group of the collection is deleted. If there are datasets in a collection that are not publicly visible, they can still be published. To do this, the complete dataset can be made publicly visible using the "Make dataset publicly available (open access)" button. Alternatively, it is also possible to publish only the metadata of a dataset. This is done via the "Publish metadata" button. This gives people the opportunity to find datasets and, if necessary, ask the respective administrator by email whether access to the files can be granted see section #4.7.3.2 Publication of the metadata of unpublished datasets.
4.7.2 Assignment of DOIs
All datasets in TUdatalib are given a unique address with a so-called handle. In addition, DOIs (Digital Object Identifier) can be assigned in TUdatalib, via which your datasets can be permanently found and cited by the public (example: https://doi.org/10.25534/tudatalib-36.9). They are comparable to a fingerprint that individually identifies each dataset.
Important: For datasets with a DOI, at least the metadata must permanently remain public
4.7.2.1 Register DOI
TUdatalib automatically reserves internally a DOI for every dataset that is archived or published in the system. This pre-reserved, but not yet registered, DOI can be viewed exclusively by admins in the "Edit this item" screen under "Status".
If the "Anonymous" group is authorized to access at least the metadata for a dataset, the administrator can request registration of the reserved DOI for this dataset in the "Edit this item" screen under "Status". The dataset will then undergo a curation procedure during which information experts from TUdata will help improve FAIRness of the data. This procedure will result in DOI registration. After sending a request for DOI registration, the request button will be hidden until there is a change made to the item's metadata.
If there are access restrictions for the metadata, DOI assignment is not possible, but you can remove the access restrictions by clicking on "Make dataset publicly available (open access)" or "Publish metadata", which makes DOI assignment possible.

If the dataset with a DOI is public, this dataset can no longer be made non-discoverable, withdrawn from or deleted in TUdatalib. If a new version of the dataset is created by clicking on "Create a new version of this dataset", the assigned DOI does not apply to the new version. A separate DOI must be assigned for each new version of a dataset in the same way as above.
If you do not want to register the DOI until later, but need the URL of the DOI now, you can use the URL automatically created and reserved by TUdatalib (but not yet registered as a DOI) that is shown on the Status page at "DOI".
4.7.2.2 Update dataset with DOI
If the metadata of a dataset with a DOI is changed in TUdatalib, the changed metadata must also be updated at the DOI agency. This is done automatically every night. Alternatively, you can click on "Update DOI" under "Status" on the "Edit dataset" page to perform this update manually immediately.
4.7.3 Changing and deleting access rights of existing items
As an admin, you have the option of making very fine-tuned settings for the authorizations of data sets. Due to the complexity, we recommend using these functions sparingly. If you have specific requirements for authorizations, please contact us. If you only want to publish datasets or metadata, you should follow the procedure in Section #4.7.3.2 Publication of the metadata of unpublished datasets or Section #4.7.3.3 Different accessibility of individual files from a dataset (partial publication).
By default, read access rights to datasets in a collection are inherited from the collection to the associated datasets. However, the access rights of a dataset (metadata and files) can also be subsequently changed by collection administrators. These rights include: READ (read access), WRITE (edit), REMOVE (reject), ADMIN, WITHDRAWN_READ.
| Community | Collection | Item (full) | Item (bundle) | Bitstream | ||
|---|---|---|---|---|---|---|
| READ | x | x | x | x | x | Read access to all content |
| WRITE | x | x | x | x | x | x |
| ADD | x | x | x | x | x | |
| REMOVE | x | x | x | x | x | |
| ADMIN | x | x | x | x | x | x |
| DELETE | x | x | x | x | ||
| WITHDRAWN_READ | x | x | ||||
| DEFAULT_BITSTREAM_READ | x | Standard read permissions for files in a collection | ||||
| DEFAULT_ITEM_READ | x | Standard read permissions for datasets (metadata) of a collection |
Existing authorizations for a dataset can be deleted individually. In addition, the permissions for metadata can be set/deleted separately from the permissions for the files.
Deleting authorizations further restricts read access to the data set, files or metadata.
You can find the screen for fine-tuned editing of authorizations by clicking on "Edit" in the navigation community and then on "Item". Search for the desired dataset in the search bar. You will then be automatically directed to the editing form. In the sub-item "Status" you will find the selection "Edit rights of data set".

4.7.3.1 Removing all restrictions from a data set
This way, all restrictions for read-access to metadata and files are deleted and the authorizations are set to "Anonymous"; the dataset is then freely available on the Internet (open access).
- It is easiest to do the same for datasets with restricted rights using the "Publish dataset completely" button under "Edit dataset" in the Status tab. This removes all previously defined restrictions for the data set (see 4.7.1).
- Alternatively, you can add READ authorizations for Anonymous individually for all entities (dataset, bundles, bitstreams) in the authorization screen.
4.7.3.2 Publication of the metadata of unpublished datasets
This deletes all restrictions for read access to the metadata and sets the permissions for this to "Anonymous"; the dataset can then be found on the network, but the actual files cannot be accessed. This gives interested parties the opportunity to find datasets and, if necessary, ask the respective administrator by email whether access to the files can be granted (see #4.7.9).
- It is easiest to do the same for datasets with restricted rights via the "Publish metadata" button under "Edit dataset" in the Status tab (see 4.7.1)
- Alternatively, you can add the READ authorization for Anonymous to the dataset and the ORIGINAL bundle in the authorization screen and leave the authorizations of the bitstreams unchanged
4.7.3.3 Different accessibility of individual files from a dataset (partial publication)
It is also possible to assign different restrictions to different files in a data set. This allows the selective publication of a subset of the files in a data set.
- In the authorization screen, you can display the bitstreams below the ORIGINAL bundle. There you can add READ authorizations for Anonymous to individual files. A READ authorization for the ORIGINAL bundle itself must also be available, otherwise the files will be hidden.
- Alternatively, click on "Edit dataset" in the navigation community and then on "Item". Selecting the edit icon for a specific file opens a new page where the permissions can be adjusted manually. To publish the corresponding file, add a READ authorization for Anonymous.
4.7.4 Editing access requests to restricted data sets
Datasets whose metadata is freely accessible can be found (but not viewed) by unauthorized users. They can then request access to the files in TUdatalib if they are interested. This access request is sent to the responsible collection administrator by email. We ask that you reply to the user. If desired, you can
- add them to the authorization group after they have logged in to TUdatalib once.
- send them a temporary link (valid for 48 hours) under which they can download a single file or all files in a data set. This granting of access is logged by the system so that it can be traced later.
4.7.5 Subsequent changes and additions to the metadata
As a community or collection administrator, you can subsequently add to or change the metadata of a dataset. To do this, click on "Edit" -> "Item" in the left-hand navigation bar and then on the "Metadata" sub-item in the editing window of your desired data set. Please note: Manually changing and adding metadata requires knowledge of the metadata standards used (Dublin Core and DataCite); the entries are not validated. You are responsible for entering the correct data in the correct format. We therefore recommend creating a new version of the dataset for additions and major changes to the metadata.
4.7.6 Showing datasets in multiple collections
The "Mapping data sets" tool can be used to display a dataset in several collections at the same time, which can be useful for collaborative projects.
To do this, click on the dataset you want to mirror and select the "Edit data set" button at the top right of the page. Select the sub-item "Collection-Mapper" on the far right and search for the target collection into which you would like to mirror the datasets under "Map new collections". Confirm your entry by clicking on "Map item to the selected collections". When a dataset is mirrored, it does not receive any new access rights. All authorizations assigned by the admin to the original collection are applied.
You need admin rights in both origin and target collection to map datasets.
4.7.7 Moving datasets between collections
Note regarding bug
Currently, due to problems with the authorization system, datasets cannot be moved between collections by local admins. We hope to fix this soon. If you would like to move a record, please contact us
Collection and community administrators can move a dataset to another collection if they have admin rights in both collections involved. To do this, click the "Move this item to another collection" button in the "Status" sub-item under "Edit item".
4.7.8 Withdrawing and deleting data sets
Only the system administrator can permanently delete an entire data set. Please contact us for this. However, community and collection administrators can withdraw datasets (in the "Status" sub-item under "Edit dataset"). These are then no longer searchable on the interface of the TUdatalib website.
4.7.9 Granting temporary access to datasets using access links
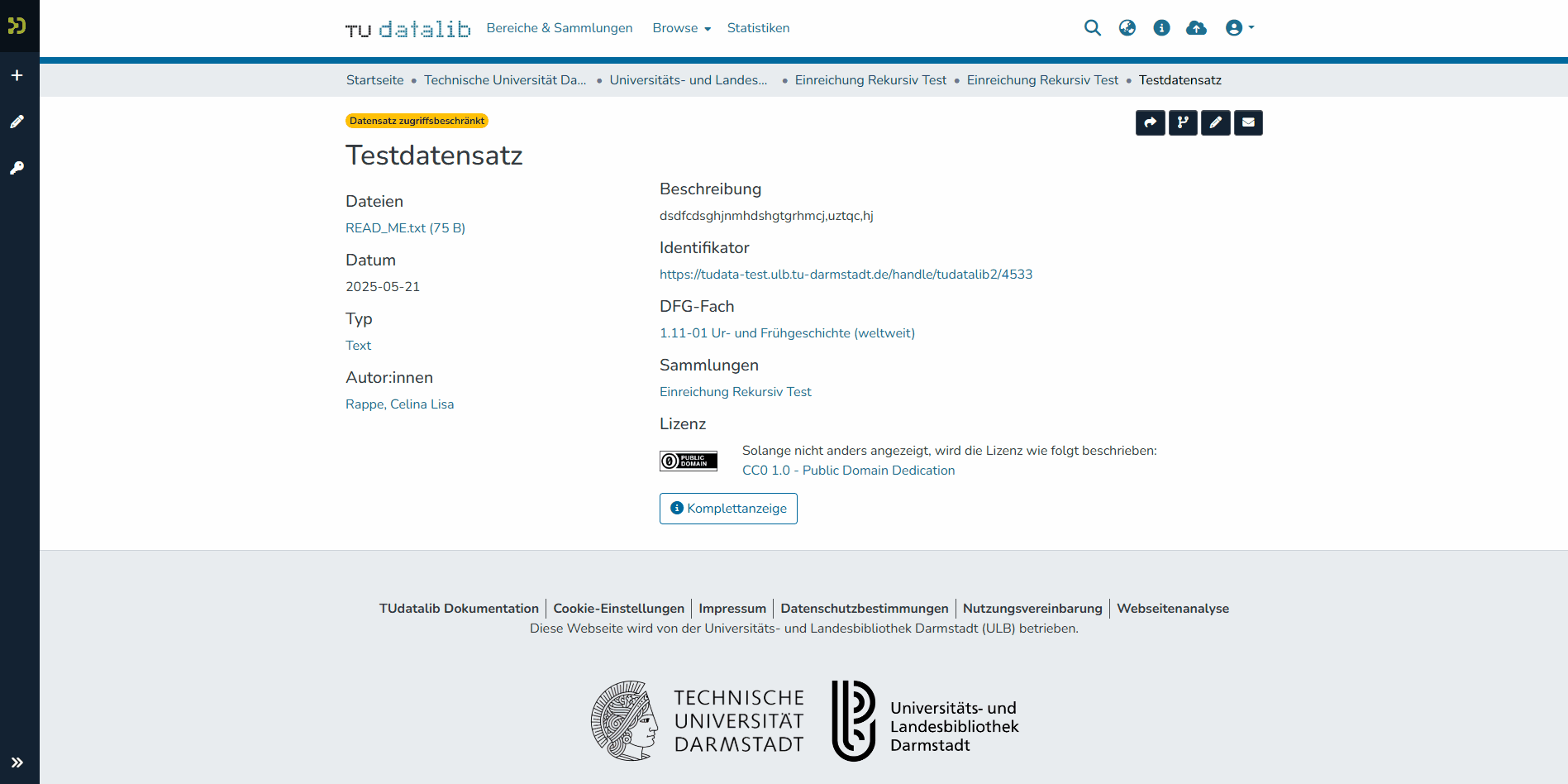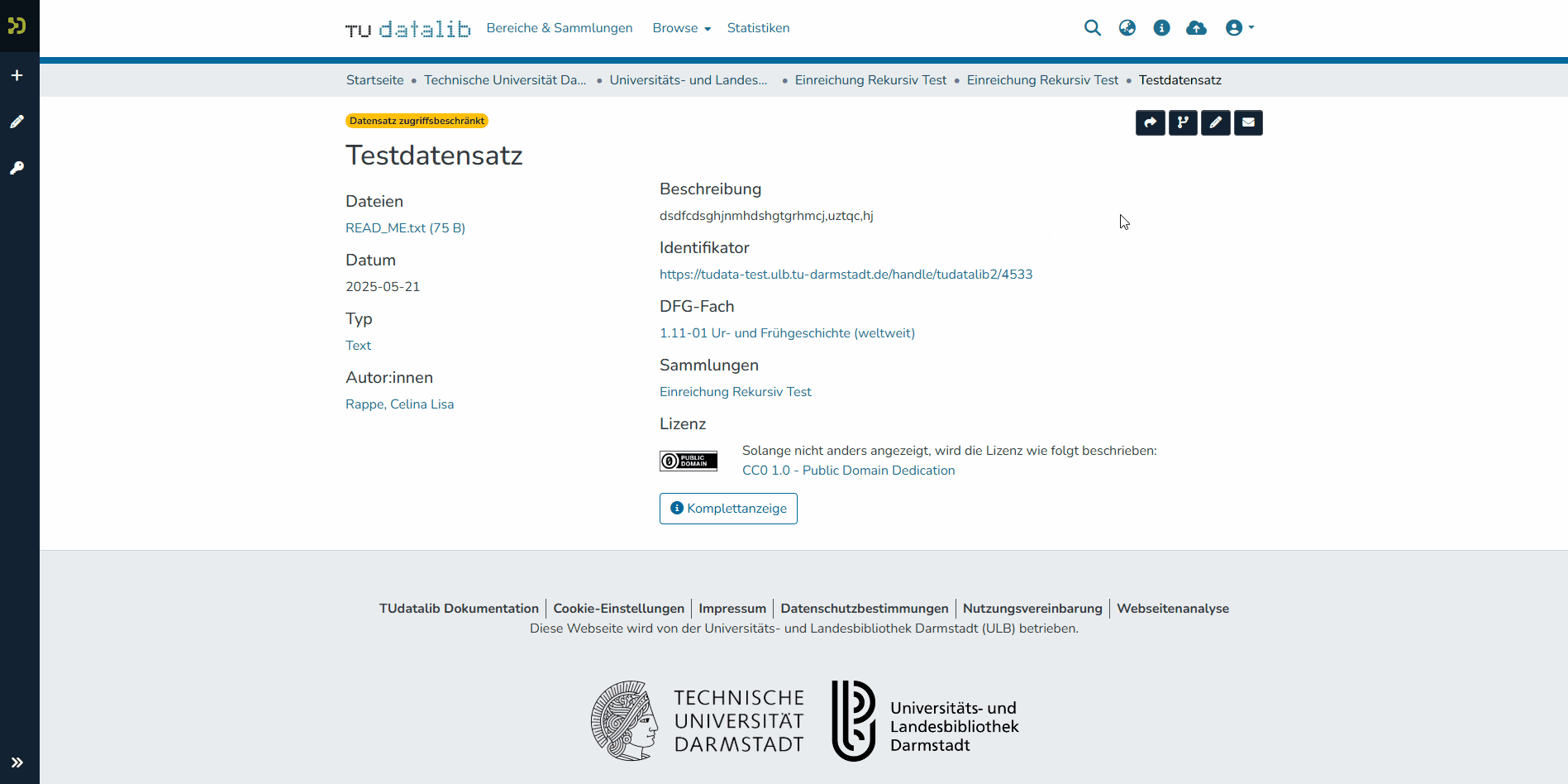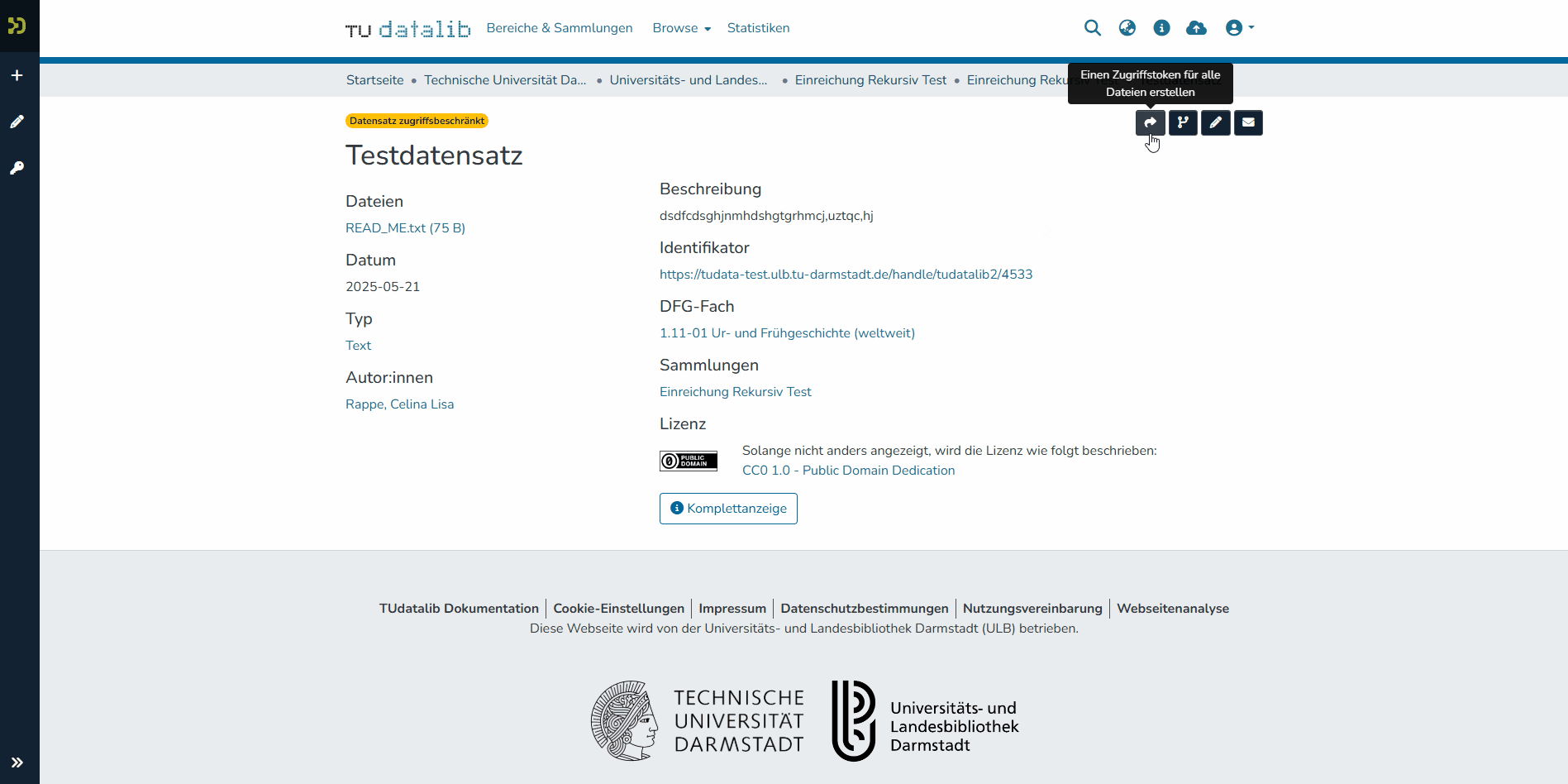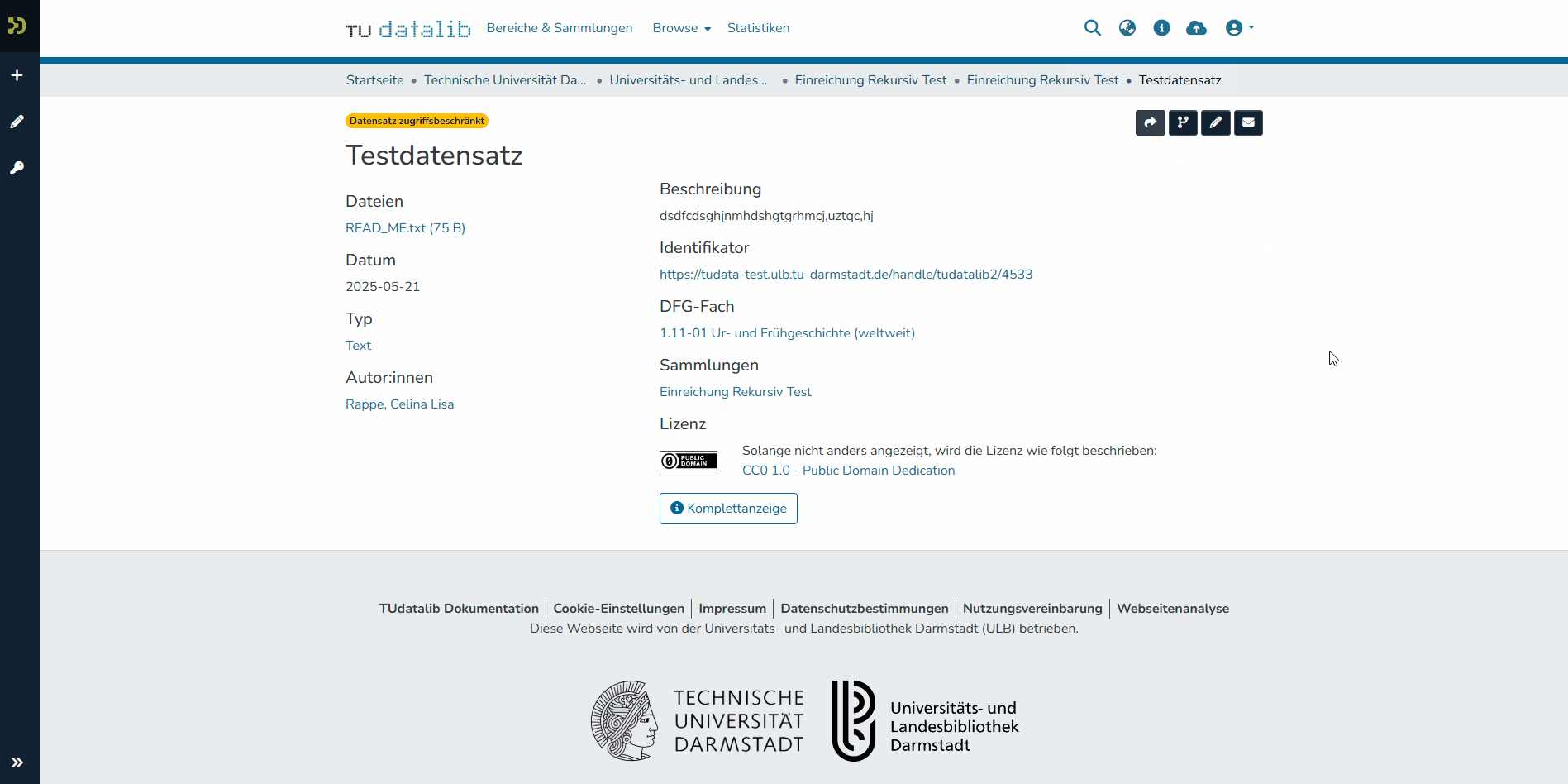
For peer reviews, for example, you may wish to grant external people temporary access to a dataset in a collection that you administer but which is not published. For this purpose, the system offers the option of generating access links that are valid for 30 days. These links can be created for individual files as well as for an entire dataset. They are created directly on the landing page of the dataset by clicking on the curved right arrow icon. You can then copy the links and pass it to them on.
4.7.10 Adding a preview image (thumbnail)
Thumbnails are usually generated automatically, e.g. when you upload a pdf. However, this is not possible for all file types.
In this case, you can add a preview image manually at a later date. To do this, go to "Edit dataset", select the sub-item "Bitstreams" and click on "Upload". You must select "Thumbnails" as the bundle for this, after which you can simply upload a jpg file from your computer and optionally add a description. This file will then be displayed as a thumbnail.
5. contact person
If you have any questions or suggestions, please contact the TUdata team.