
EUR-Lex Dataset
| dc.contributor.author | Loza Mencia, Eneldo | |
| dc.contributor.author | Fürnkranz, Johannes | |
| dc.contributor.author | loza | |
| dc.date.accessioned | 2021-09-27T00:16:16Z | |
| dc.date.available | 2021-09-27T00:16:16Z | |
| dc.date.issued | 2010 | |
| dc.identifier.uri | https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/2937 | |
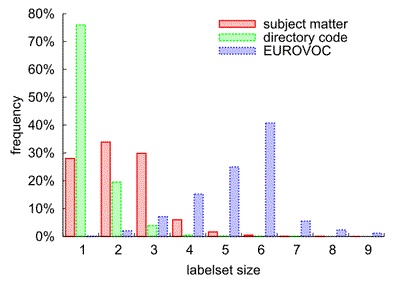
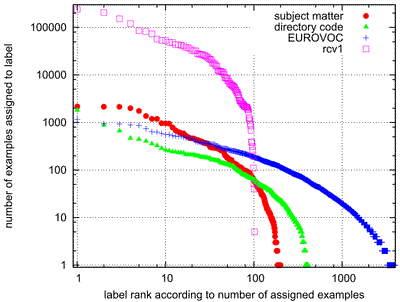
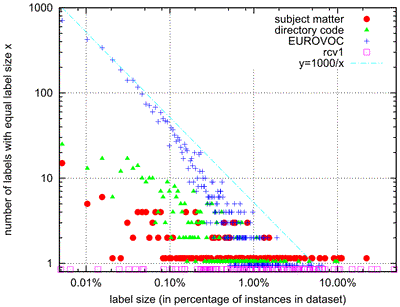
| dc.description | The EUR-Lex text collection is a collection of documents about European Union law. It contains many different types of documents, including treaties, legislation, case-law and legislative proposals, which are indexed according to several orthogonal categorization schemes to allow for multiple search facilities. The most important categorization is provided by the EUROVOC descriptors, which form a topic hierarchy with almost 4000 categories regarding different aspects of European law. This document collection provides an excellent opportunity to study text classification techniques for several reasons: - it contains multiple classifications of the same documents, making it possible to analyze the effects of different classification properties using the same underlying reference data without resorting to artificial or manipulated classifications, - the overwhelming number of produced documents make the legal domain a very attractive field for employing supportive automated solutions and therefore a machine learning scenario in step with actual practice, - the documents are available in several European languages and are hence very interesting e.g. for the wide field of multi- and cross-lingual text classification, - and, finally, the data is freely accessible (at http://eur-lex.europa.eu/) The database constitutes a very challenging multilabel scenario due to the high number of possible labels (up to 4000). A first step towards analyzing this database was done by applying multilabel classification techniques on three of its categorization schemes in the following work: Eneldo Loza Mencía and Johannes Fürnkranz. Efficient multilabel classification algorithms for large-scale problems in the legal domain. In Semantic Processing of Legal Texts, pages 192-215, Springer-Verlag, 2010 http://www.ke.tu-darmstadt.de/publications/papers/loza10eurlex.pdf | de_DE |
| dc.language.iso | en | de_DE |
| dc.relation | IsSupplementTo;DOI;10.1007/978-3-540-87481-2_4 | |
| dc.relation | IsSupplementTo;DOI;10.1007/978-3-642-12837-0_11 | |
| dc.rights.uri | https://rightsstatements.org/vocab/InC/1.0/ | |
| dc.subject | Multi-label classification | de_DE |
| dc.subject | EUR-Lex | de_DE |
| dc.subject | EUROVOC | de_DE |
| dc.subject.classification | 4.43-04 Künstliche Intelligenz und Maschinelle Lernverfahren | de_DE |
| dc.subject.classification | 4.43-05 Bild- und Sprachverarbeitung, Computergraphik und Visualisierung, Human Computer Interaction, Ubiquitous und Wearable Computing | |
| dc.subject.ddc | 004 | |
| dc.title | EUR-Lex Dataset | de_DE |
| dc.type | Dataset | de_DE |
| dc.type | Text | de_DE |
| dc.description.version | Version 2010 | de_DE |
| tud.unit | TUDa | |
| tud.history.classification | Version=2016-2020;409-05 Interaktive und intelligente Systeme, Bild- und Sprachverarbeitung, Computergraphik und Visualisierung |
Dateien zu dieser Ressource

Der Datensatz erscheint in:
Solange nicht anders angezeigt, wird die Lizenz wie folgt beschrieben: in Copyright