
Daten zu: Elektronische Laborbücher an der TU Darmstadt - Beispiel für ein strategisches Vorgehen
| dc.contributor.advisor | ||
| dc.contributor.author | Marutschke, Christoph | |
| dc.contributor.author | Jagusch, Gerald Wolfgang | |
| dc.contributor.author | Fuhrmans, Marc | |
| dc.date.accessioned | 2020-07-09T07:51:56Z | |
| dc.date.available | 2020-06-08T10:13:45Z | |
| dc.date.available | 2020-07-09T07:51:56Z | |
| dc.date.issued | 2018 | |
| dc.identifier.uri | https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/2344.2 | |
| dc.identifier.uri | https://doi.org/10.25534/tudatalib-208.2 | |
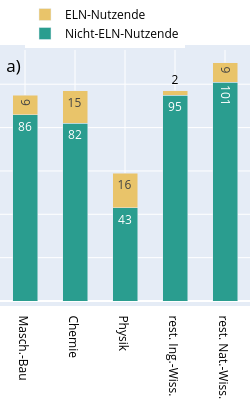
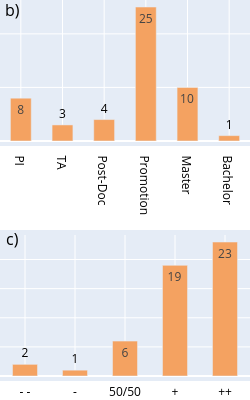
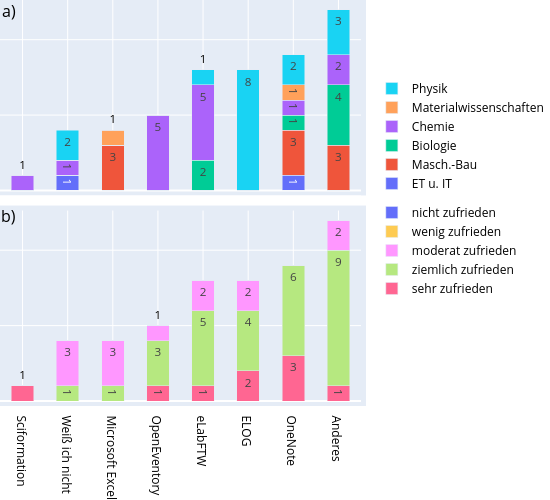
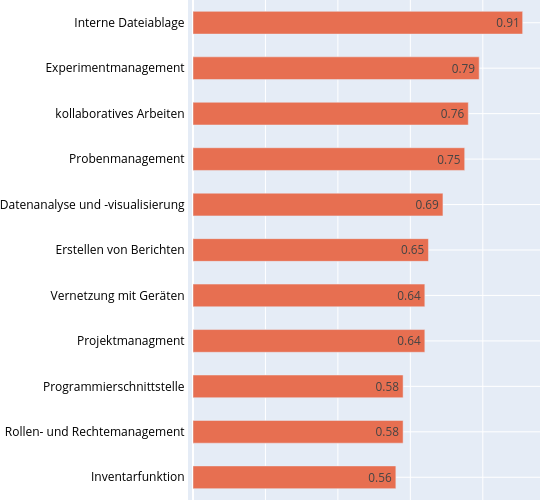
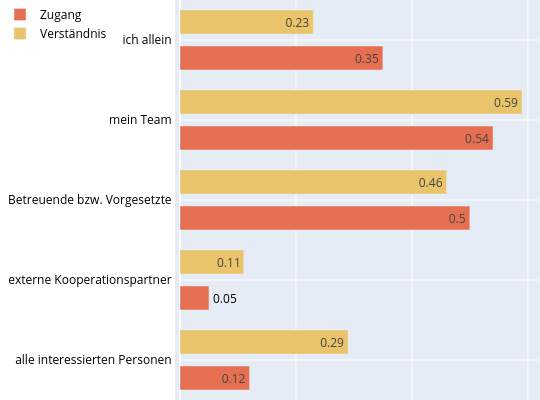
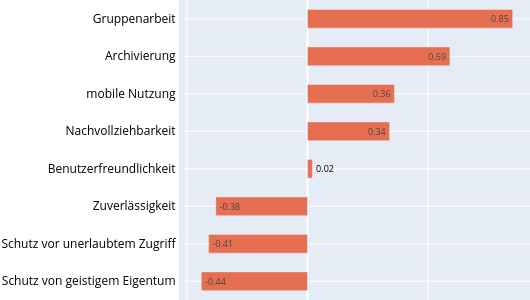
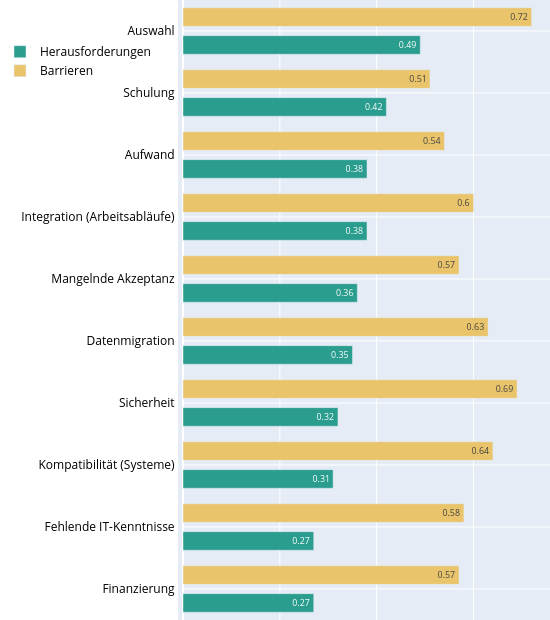
| dc.description | <p>Die Daten entstanden im Rahmen eines (Bibliotheks-)Referendar-Projekts zum Thema Elektronische Laborbücher (ELN). Die Umfrage "<strong>Elektronische Laborbücher im akademischen Umfeld - Eine Umfrage zur Nutzung an der Technischen Universität Darmstadt</strong>" soll die Verbreitung und typischen Nutzungsszenarien von ELNs untersuchen und das Thema für ein universitätsweites Forschungsdatenmanagement aufbereiten.</p> <p>Die Daten wurden außerdem für eine Masterarbeit (Library & Information Science) an der Humboldt-Universität zu Berlin verwendet.</p> <p>Der vollständige Fragebogen findet sich in deutscher und englischer Sprache in der Datei: <em>fragebogen.pdf</em>. Die Umfrage wurde durchgeführt mit Hilfe der Hochschuldidaktischen Arbeitsstelle unter Verwendung der Software <strong>EvaSys</strong>.</p> <p>Zeitraum der Datenerhebung:</p> <ul> <li>08.03.2018 bis 02.04.2018</li> </ul> <p>Zielgruppe:</p> <ul> <li>Alle Mitglieder der natur- und ingenieurwissenschaftlichen Fachbereiche an der Technischen Universität (TU) Darmstadt.</li> <li>Insgesamt haben 460 Personen an der Umfrage teilgenommen.</li> </ul> <h4 id="struktur-der-rohdaten">Struktur der Rohdaten</h4> <p>Die Ergebnisdaten der Umfrage wurden von der Hochschuldidaktischen Arbeitsstelle in sechs CSV-Dateien (zwecks Zwischenstandsanalyse) bereitgestellt: </p> <ul> <li><em>sys_34-Befragung_zu_Elektronischen_Laborbüchern</em></li> <li><em>sys_34-Befragung_zu_Elektronischen<em>Laborbüchern</em>-_Studenten - Gruppe_1</em></li> <li><em>sys_34-Befragung_zu_Elektronischen<em>Laborbüchern</em>-_Studenten - Gruppe_2</em></li> <li><em>sys_34-Befragung_zu_Elektronischen<em>Laborbüchern</em>-_Studenten - Gruppe_3</em></li> <li><em>sys_34-Befragung_zu_Elektronischen<em>Laborbüchern</em>-_Studenten - Gruppe_4</em></li> <li><em>sys_34-Erster Datensatz mit Schreibfehlern (in einer der Fragen)</em></li> </ul> <p>und dann zur Datei <em>eln_data.csv</em> zusammengeführt. Vorgehen unter Linux via:</p> <pre><code class="lang-bash"><span class="hljs-selector-tag">cat</span> *<span class="hljs-selector-class">.csv</span> > <span class="hljs-selector-tag">eln_data</span><span class="hljs-selector-class">.csv</span> </code></pre> <h4 id="aufbereitung-der-rohdaten">Aufbereitung der Rohdaten</h4> <p>Vor der Auswertung wurden in den Rohdaten folgende Veränderungen vorgenommen (<em>eln_data.csv</em> -> <em>eln_data_mod.csv</em>):</p> <ul> <li><p>Zusammenführung von verschiedenen aber gleichwertigen Positionsbezeichnungen (z.B. Akademischer Rat zu Leitender Wissenschaftlicher Mitarbeiter) und Fachbezeichnungen für eine einheitliche Zusammenfassung universitärer Statusgruppen & Fachbereiche/Institute.</p> </li> <li><p>Die Spaltenbezeichnungen der Teilergebnisse wurden entfernt und für die leichtere Handhabbarkeit auf einen durchgehenden Index reduziert. (z.B. In welcher Stellung befinden Sie sich? -> 00001)</p> </li> <li><p>Streichung eines einzigen Nicht-ELN-Nutzers aus dem Fachbereich der Mathematik, weil es sich bei der Mathematik nicht um ein Fach mit starker Labor(buch)kultur handelt (und diese Person auch keins verwendete).</p> </li> </ul> <p>Die für die Umfrage verwendete Software <strong>EvaSys</strong> gibt die Rohdaten in Form von Zahlen aus, die mithilfe des Kodebuchs (codebook.pdf) wieder in die ausgeschriebenen Antworten (und Skalen) zurückübersetzt werden müssen. Diese Schlüssel-Werte Paare sind zudem für die maschinelle Verarbeitung in der Datei <em>parm.yml</em> festgehalten.</p> <p>Bei manchen Skalenantworten verzichtete die Software EvaSys (im Kodebuch) zudem auf die explizite Angabe der ursprünglichen Werte (Ursache unklar). In diesen Fällen folgt die Reihenfolge der Antworten trotzdem der in der Frage angegebenen Skala, z.B. wurden als Antwortmöglichkeit fünf Stufen von <em>sehr herausfordernd</em> bis <em>unproblematisch</em> angegeben, so übersetzt die Software das in die Werte 1 bis 5, wobei 1 = sehr herausfordernd und 5 = unproblematisch gilt.</p> <h4 id="verarbeitung-der-daten">Verarbeitung der Daten</h4> <p>Die Daten wurden mittels der Python-Skripte (Ordner <strong>code/</strong>): <em>analysis.py</em> und <em>gfx.py</em> ausgewertet und visualisiert. Wichtige Parameter zur Auswertung sind in den YAML-Dateien: <em>jobs.yml</em> und <em>parm.yml</em> als Schlüssel-Werte-Paare hinterlegt. Die Auswertung basiert ausschließlich auf der Datei <em>eln_data_mod.csv</em> und erfolgt immer komplett in einem Durchlauf.</p> <p>Das Skript <em>analysis.py</em> organisiert die Auswertungen anhand der Vorgaben in der Steuerungsdatei <em>jobs.yml</em>. Darin ist festgelegt welche Frage nach welchem Muster ausgewertet werden soll (z.B. mit oder ohne Skala, als Gesamtübersicht oder anhand bestimmter Kategorien gruppiert).</p> <p>Der Code für die die Erstellung aller Abbildungen (mit <a href="https://plotly.com/">Plotly</a>) findet sich in der Datei <em>gfx.py</em>.</p> <p>Die Verwaltung der Software-Packages und ihrer Abhängigkeiten für die verwendete Python-Version 3.7 erfolgte durch die Software <a href="https://python-poetry.org/">Poetry</a>. Für die Erzeugung einer passenden Entwicklungsumgebung finden sich die Dateien <em>poetry.lock</em> und <em>pyproject.toml</em> im Ordner <strong>code/</strong>.</p> <pre><code class="lang-bash">poetry <span class="hljs-keyword">shell</span> poetry <span class="hljs-keyword">update</span> </code></pre> <h4 id="ergebnisse">Ergebnisse</h4> <p>Die aggregierten Daten im Ordner <strong>data/</strong> folgen der folgenden Konvention:</p> <ul> <li><p>Das Präfix <em>gfx_</em> ist (nur) ein Hinweis darauf, dass sich diese Daten sinnvoll ohne weitere Bearbeitung plotten lassen.</p> </li> <li><p>Die Analyse(n) wurden anhand der folgenden Kernkategorien (z.B. ELN-Nutzer & Nicht-Nutzer) durchgeführt:</p> <ul> <li><em><em>discipline</em></em> = Fachliche Ausrichtung der Teilnehmer</li> <li><em><em>focus</em></em> = Experimentelle bzw. theoretische Arbeitsweise</li> <li><em><em>user</em></em> = Nutzer und Nicht-Nutzer von Elektronischen Laborbüchern</li> <li><em><em>position</em></em> = Zugehörigkeit zu einer universitären Statusgruppe</li> </ul> </li> <li><p>Fragen, die eine Skala beinhalten wurden entsprechend einer passenden Umrechnungstabelle in <em>parm.yml</em> (prefix = <em>scale_dict_</em>) auf einen repräsentativen Wert umgerechnet. Diese Auswertungen wurden mit <em><em>scale</em></em> (bzw. <em><em>no-scale</em></em>) gekennzeichnet.</p> </li> <li><p>Die Summe aller Teilnehmerantworten auf eine bestimmte Kategorie wird in gesonderten Dateien ausgewiesen (und nicht als Extra-Spalte in der dazugehörigen Tabelle). Dies wird durch das Kürzel <em><em>gesamt</em></em> angedeutet. Bei der Auswertung im Modus <em><em>no-scale</em></em> ergibt sich (natürlich) für jede der untersuchten Kernkategorien (<em><em>user</em></em>, <em><em>focus</em></em>, <em><em>position</em></em> & <em><em>discipline</em></em>) ein sehr ähnliches Ergebnis. Nur ähnlich und nicht gleich (wie man es vielleicht auf den ersten Blick erwarten würde) - weil natürlich nicht jeder Teilnehmende alle Fragen vollständig beantwortet hat, d.h. die Gesamtzahl der Antworten nicht gleich ist.</p> </li> </ul> <p>Für die Auswertung anhand der Fachdisziplin wurde neben der im Fragebogen angebotenen Kategorien eine stärker zusammenfassende Aufteilung verwendet (Maschinenbau, Chemie, Physik, rest. Ing.-Wis., rest. Nat.-Wis.) Die Verwendung dieser Aufteilung wird anhand der Kürzel <em>cluster-one</em> bzw. <em>no-cluster</em> angegeben. Aufgrund einer Designschwäche erzeugt das Script automatisch auch entsprechende Dateien für die anderen Kernkategorien - was zu ungewollten und unsinnigen Dubletten führt. So besteht z.B. kein Unterschied zwischen der Datei <em>gfx_cluster-one_scale_user_lab.csv</em> und <em>gfx_no-cluster_scale_user_lab.csv</em>, weil hier die Arbeitsweise und nicht die fachliche Ausrichtung der Teilnehmer betrachtet wird. Glücklicherweise lassen sich Dubletten solch kleiner Dateien schnell mit entsprechenden Programmen (unter Linux z.B. <strong>rmlint</strong>) finden und bei Bedarf löschen.</p> <p>Die betrachtete Frage wird durch ein Stichwort am Ende des Dateinamen (und der Angabe des Index der Frage in <em>eln_data_mod.csv</em> in der Datei) vermerkt.</p> <table> <thead> <tr> <th>Stichwort</th> <th>Frage</th> </tr> </thead> <tbody> <tr> <td><strong>access</strong></td> <td>Wer hat alles Zugriff auf Ihr (elektronisches oder papiergebundenes) Laborbuch?</td> </tr> <tr> <td><strong>automation</strong></td> <td>Schätzen Sie bitte den Automatisierungsgrad der Datendokumentation in Ihrem Arbeitsumfeld!</td> </tr> <tr> <td><strong>barriers</strong></td> <td>Welche Aspekte sehen Sie als Herausforderung bei der Einführung eines elektronischen Laborbuchs?</td> </tr> <tr> <td><strong>central_eln</strong></td> <td>Wäre ein von der TU Darmstadt zentral für alle angebotenes elektronisches Laborbuch für Sie interessant?</td> </tr> <tr> <td><strong>challenges</strong></td> <td>Welche Aspekte haben sich Ihnen tatsächlich als Herausforderungen bei der Einführung eines elektronischen Laborbuchs gestellt?</td> </tr> <tr> <td><strong>comparison</strong></td> <td>Sehen Sie bezüglich der folgenden Aspekte ein elektronisches (ELN) oder ein papiergebundenes Laborbuch (PLN) im Vorteil?</td> </tr> <tr> <td><strong>eln</strong></td> <td>Arbeiten Sie zurzeit mit einem elektronischen Laborbuch (ELN), um Ihre Experimente und Projekte zu dokumentieren und/oder mit anderen zu teilen?</td> </tr> <tr> <td><strong>features</strong></td> <td>Welche Funktionen würden Sie - neben der Dokumentation von Experimenten - von einem elektronischen Laborbuch erwarten?</td> </tr> <tr> <td><strong>financing</strong></td> <td>Wären Sie bereit für ein ELN Geld auszugeben?</td> </tr> <tr> <td><strong>happyness</strong></td> <td>Wie zufrieden sind Sie mit dem genutzten ELN?</td> </tr> <tr> <td><strong>lab</strong></td> <td>Schätzen Sie bitte den Automatisierungsgrad & Standardisierungsgrad der Datendokumentation in Ihrem Arbeitsumfeld!</td> </tr> <tr> <td><strong>understanding</strong></td> <td>Wer kann die Einträge in Ihrem Laborbuch nachvollziehen und gegebenenfalls die beschriebenen Experimente/Messungen wiederholen?</td> </tr> </tbody> </table> <h4 id="nutzungsrechte-und-lizenz">Nutzungsrechte und Lizenz</h4> <p>Für den bestmöglichen Datenschutz wird ein Einblick in die Rohdaten nur auf Anfrage ermöglicht. Die aggregierten (und vollständig anonymisierten) Daten können hingegen nach <a href="https://creativecommons.org/licenses/by/4.0/">CC-BY-4.0</a>) genutzt werden. Weitere Zusammenstellungen können auf Anfrage an die Autoren bereitgestellt werden.</p> | en_US |
| dc.language.iso | de | en_US |
| dc.relation | IsReferencedBy;DOI;10.17192/bfdm.2020.2.8282 | |
| dc.relation.isreferencedby | IsReferencedBy;DOI;10.17192/bfdm.2020.2.8282 | |
| dc.rights | Creative Commons Attribution 4.0 | |
| dc.rights.uri | https://creativecommons.org/licenses/by/4.0/ | |
| dc.subject | Survey | en_US |
| dc.subject | ELN | en_US |
| dc.subject | Electronic Lab Notebook | en_US |
| dc.subject.classification | 409-06 Informationssysteme, Prozess- und Wissensmanagement | en_US |
| dc.subject.ddc | 004 | |
| dc.subject.ddc | 004 | |
| dc.title | Daten zu: Elektronische Laborbücher an der TU Darmstadt - Beispiel für ein strategisches Vorgehen | en_US |
| dc.type | Dataset | en_US |
| dc.type | Software | en_US |
| dc.type | Image | en_US |
Dateien zu dieser Ressource








Der Datensatz erscheint in:

Solange nicht anders angezeigt, wird die Lizenz wie folgt beschrieben: Creative Commons Attribution 4.0